Chatboti s umělou inteligencí jsou tak rozsáhlí a složití, že ani společnosti, které je vyvíjejí, nedokážou předvídat jejich chování. Proto někdy chatboti odpovídají škodlivými, nezákonnými nebo znepokojivými zprávami. Současná řešení zahrnují ruční poskytování zpětné vazby, ale existuje nové navrhované řešení od Anthropic, výzkumné společnosti, kterou založili bývalí zaměstnanci OpenAI. Informoval o tom server The Verge a Ars Technica.
Anthropic je ve světě umělé inteligence trochu neznámou společností. Chce se prezentovat jako startup zabývající se umělou inteligencí s ohledem na bezpečnost. Společnost získala velké finanční prostředky (včetně 300 milionů dolarů od Googlu) a nedávno se zúčastnila diskuse o AI regulacích v Bílém domě spolu se zástupci společností Microsoft a Alphabet. Přesto je firma pro širokou veřejnost prázdným pojmem. Jejím jediným produktem je chatbot jménem Claude, který je dostupný především prostřednictvím služby Slack.
AI startup Anthropic wants to write a new constitution for safe AI https://t.co/xryCQWVKOU pic.twitter.com/ADuXOrQkdO
— The Verge (@verge) May 9, 2023
Jak uvedl server Ars Technica, společnost se nyní zaměřuje na způsob, jak učinit umělou inteligenci bezpečnou. Podle spoluzakladatele Jareda Kaplana společnost v současné době vyvíjí metodu známou jako „constitutional AI“. Jedná se o způsob, jak naučit AI systémy, jako jsou chatboti, dodržovat určité soubory pravidel.
AI bude dohlížet samo na sebe
„Ústavní umělá inteligence funguje tak, že systém umělé inteligence dohlíží sám na sebe na základě konkrétního seznamu ústavních principů,“ uvedl Jared Kaplan. Předtím, než odpoví na výzvy uživatele, zváží chatbot možné odpovědi a na základě pokynů v ústavě učiní nejlepší volbu. Podle Kaplana je v systému Anthropic stále zapojena zpětná vazba od uživatele, ale je jí mnohem méně než v současnosti.
„To znamená, že nepotřebujete zástupy pracovníků, kteří by třídili škodlivé výstupy, abyste model v podstatě opravili,“ řekl Kaplan. „Tyto principy můžete velmi jasně formulovat a můžete je velmi rychle měnit. V podstatě můžete model jen požádat, aby si přegeneroval svá vlastní tréninková data a tak trochu se přeškolil.“
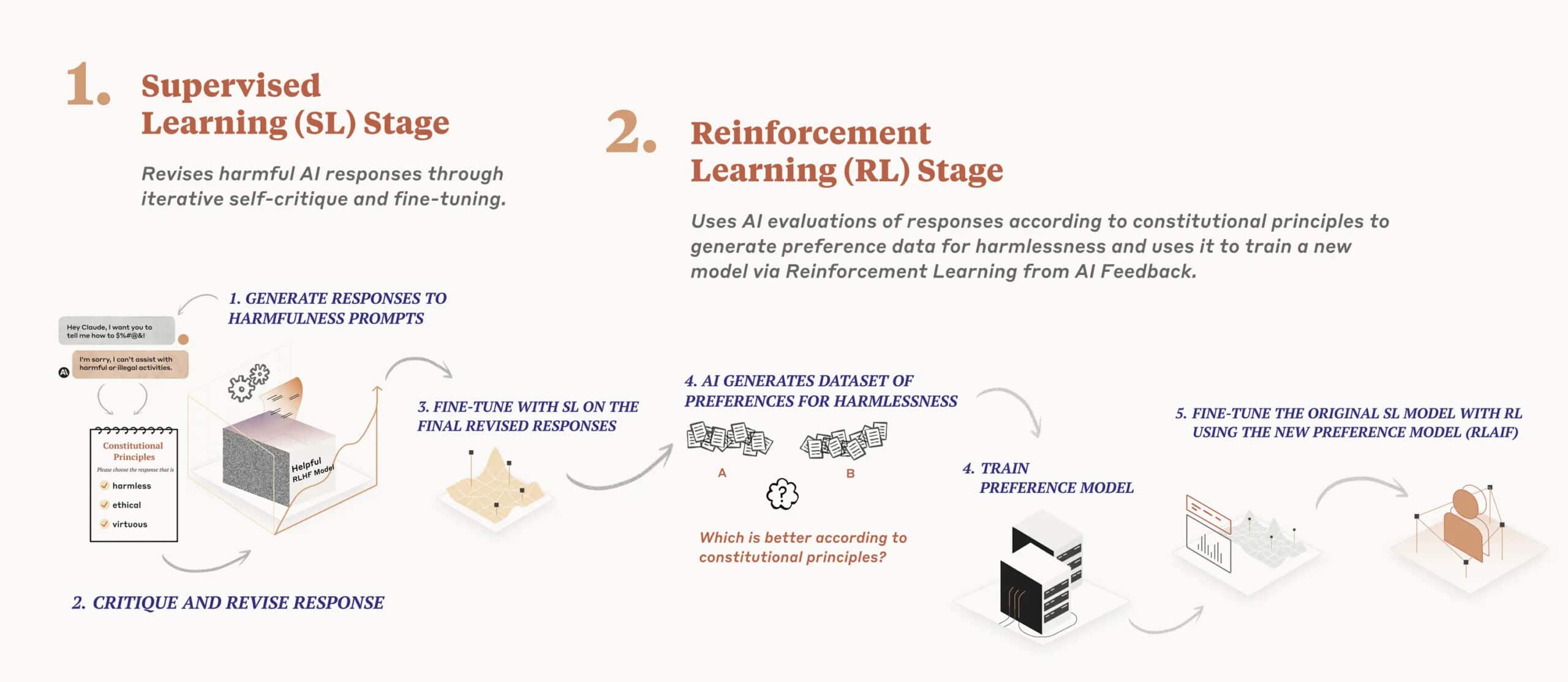
Zde jsou například tři ústavní principy AI Anthropic převzaté ze Všeobecné deklarace lidských práv:
- Vyber odpověď, která nejvíce podporuje a povzbuzuje život, svobodu a osobní bezpečnost.
- Vyber odpověď, která nejvíce odrazuje od mučení, otroctví, krutosti a nelidského či ponižujícího zacházení a je proti nim.
- Vyber odpověď, která je nejméně rasistická a sexistická a která je nejméně diskriminační na základě jazyka, náboženství, politického nebo jiného názoru, národnostního nebo sociálního původu, majetku, rodu nebo jiného postavení.
Společnost připouští, že vzhledem k pluralitě hodnot ve světě mohou být v různých kulturách zapotřebí různé přístupy k pravidlům. Modely umělé inteligence budou mít „hodnotové systémy“, ať už záměrné, nebo nezáměrné, uvádí Anthropic.
